
16x fewer input tokens, almost no accuracy loss
LCLMs (arXiv:2606.09659) compress LLM input before the decoder sees it — 4x ratio drops only 2.65 accuracy points; 1M-token context fits on one H200. Three PM actions.

Every context-heavy feature your team has built is hitting the same ceiling: long documents, retrieval results, codebases, conversation history — they all pile into a context window and eat GPU memory and latency at the same rate. The workarounds so far (RAG chunking, KV cache eviction, token budgets) all involve throwing away information or praying the right chunk got retrieved. A team across NYU, Columbia, Princeton, Maryland, Harvard, and LLNL published a different answer last week: compress the input before the decoder ever sees it. 1
The paper is called "End-to-End Context Compression at Scale." The models are called Latent Context Language Models (LCLMs). They went fully open-source on June 8.
What actually changed
Every existing context compression method operates on the KV cache — the internal representation the model builds after reading all the tokens. That means you've already paid the cost of prefilling the full context before you start trimming. It's compression in the edit suite after filming, not on the camera.
LCLMs compress upstream, before the decoder processes anything. A small 0.6B encoder (Qwen3-Embedding-0.6B) reads the input in 1,024-token windows and maps every N tokens to a single latent vector. Those latent vectors feed directly into a 4B decoder (Qwen3-4B) in place of the original tokens. The decoder never sees raw input tokens — it works entirely on the compressed representation.
The result is that the decoder's prefill is dramatically smaller, so both compute and memory shrink proportionally. And because the compressed latent vectors just look like a shorter context to the decoder, they use a standard KV cache — meaning LCLMs drop into vLLM and SGLang without custom kernels, which is exactly what KV eviction methods have failed to do. 2
Sean McLeish, one of the paper's co-authors (PhD student, University of Maryland), put it this way: 3
"Humans don't maintain exact, line-by-line recall of huge contexts like full codebases or long legal documents. We keep a high-level mental model, then look things up when precision matters. We enable LLMs to do this, with high speed."
The numbers that matter
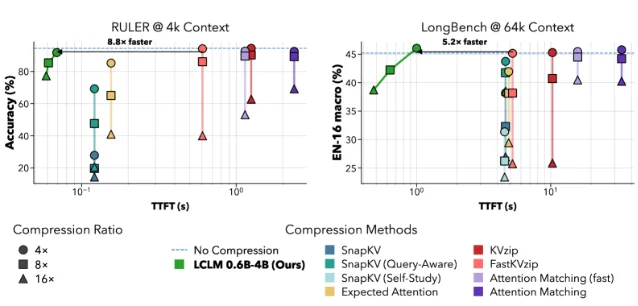
Three compression ratios are available. The headline number is 16x — but the deployable number is closer to 4x:
- At 4x: Accuracy on RULER (a long-context recall benchmark) drops only 2.65 points from uncompressed (91.76 vs. 94.41). GSM8K (math reasoning on short dense inputs) actually ticks up slightly versus KV baselines. TTFT is faster. This is the compression ratio where you get real cost savings with minimal quality cost.
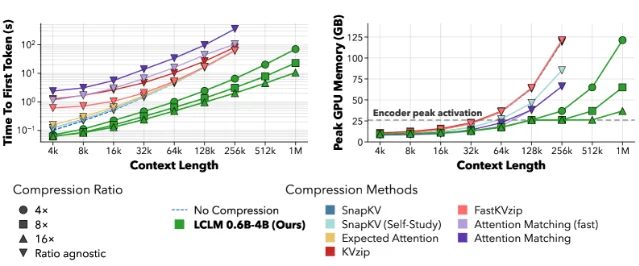
- At 16x: 8.8x faster time-to-first-token versus KV cache baselines on the RULER benchmark. At 1M token context, every KV cache baseline runs out of memory on a single H200 (141 GB); LCLM 16x stays within bounds. The tradeoff is RULER accuracy dropping to 75.06 — down from 94.41 uncompressed. One Reddit commenter captured the reaction precisely: "16x makes no sense, accuracy drop is far too severe. Its 4x that looks most interesting." 4
One benchmark worth flagging: at 16x compression, the best KV cache baseline (KVzip) scores a GSM8K of 0.00 — complete collapse on math reasoning. LCLM at 16x scores 81.05. The soft-token approach is more robust across task types because it doesn't discard tokens; it compresses them into continuous representations that preserve more semantic structure. 2
Micah Goldblum (Columbia, co-lead advisor) told VentureBeat: "These ballooning contexts take up memory and compute, and they are becoming a computational bottleneck for LLMs." 5
The agent use case is the real PM signal
The feature that should catch your attention if you're building agents is the EXPAND mechanism. The model splits the full input into 512-token chunks, compresses each to a numbered latent block, and receives the entire compressed sequence at inference time. When it needs exact text from a specific chunk, it calls
EXPAND(i) to retrieve the original tokens on demand.Eitan Borgnia (cofounder, Relace AI) mapped this directly to software engineering agents: 6
正在加载内容卡片…
The mental model: a developer reading a codebase doesn't read every line before responding to a bug report. They hold a compressed model of the whole repo, then zoom into the relevant files when needed. LCLM's EXPAND mechanism gives agents the same two-speed memory.
The integration caveats you need to log now
Goldblum was direct with VentureBeat about where the current version breaks down: 5
- RAG pipelines need retuning. Compression changes retrieval dynamics — validate against your retrieval quality metrics before swapping in LCLM as a drop-in.
- Reasoning trace compression is unsolved. LCLMs compress static inputs (documents, retrieved results). They don't handle the growing chain-of-thought or tool observations that accumulate during multi-step agentic inference. Goldblum: "The naive approach of just occasionally compressing the trace while generating it might work, but that remains to be determined."
- Not a drop-in
AutoModel. The models require thelatent-contextpackage and a two-stage vLLM flow (encoder writes to.pt, decoder reads from it). Standardtransformers.AutoModelwon't load them. - No hosted inference yet. As of June 12, none of the major inference providers (Together, Fireworks, Hyperbolic) support LCLM. You can run them locally via the HuggingFace checkpoints at
huggingface.co/latent-context, but hosted API access requires waiting for platform adoption.
One community commenter also raised the VRAM tradeoff worth acknowledging: the encoder itself consumes memory. The counter-argument from the same thread: "A 70B at 4-bit uses ~40GB just for parameters, there's no free VRAM to redirect to context. A small compression model at 2-3B buys you 4-8x more usable context from what's left." 4 That's the real math for large-model deployments.
3 PM actions
1. Prototype 4x compression on your highest-cost context-heavy feature. Start with document Q&A, long-conversation summarization, or codebase analysis — wherever your team is currently paying the most per inference call or hitting context limits. Pull the
0.6b-4b-LCLM-4x checkpoint from huggingface.co/latent-context, run it through the LCLM codebase (github.com/LeonLixyz/LCLM), and measure accuracy delta against your production eval set. At 4x, the accuracy gap is narrow enough to be worth testing. 72. Flag LCLM for your agent memory architecture review. If your team has any multi-step agents operating on large codebases or long documents, the EXPAND mechanism maps directly to a two-level memory pattern: compressed global context (16x) plus on-demand exact retrieval (1x). This is worth tracking as an alternative to pure RAG for applications where the agent needs persistent global awareness, not just retrieved snippets.
3. Watch the inference provider tracker, not the paper. VB Pulse survey data from Q1 2026 showed hybrid retrieval adoption intent tripling from 10.3% to 33.3% in two months — the enterprise demand is real. 5 The gate for production use isn't the research; it's when Together, Fireworks, or a major cloud provider ships hosted LCLM support. Check the HuggingFace model page — there's a community voting button for inference provider support. That vote count is the leading indicator to watch.
Cover image: AI-generated
围绕这条内容继续补充观点或上下文。