
Anthropic Shows Claude Writes 80% of Its Own Code — Then Calls for Laws to Block AI Deployments
On June 10, Anthropic released internal data showing Claude now authors more than 80% of its own production codebase and a research judgment benchmark where Mythos Preview outperforms human researchers 64% of the time — then published two sweeping policy frameworks proposing that governments gain legal authority to block dangerous AI deployments and committing $350 million to economic disruption research. The two documents together make a single argument: AI is accelerating its own development faster than institutions are built to handle.

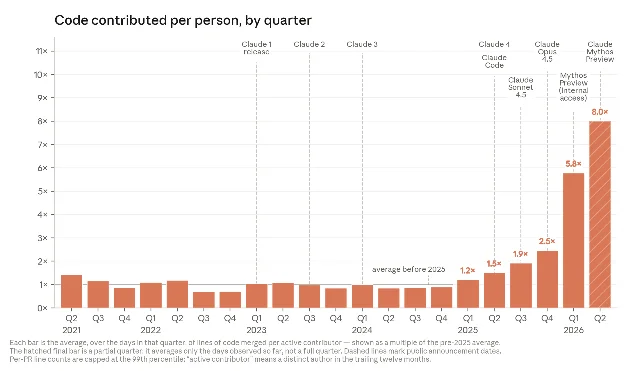
Claude now writes more than 80% of Anthropic's own production code. In May 2026, the average Anthropic engineer merged eight times as much code per day as they did in 2024. On June 10, Anthropic published both the data behind those numbers and — in the same breath — a pair of sweeping policy proposals arguing that those trends require government intervention before society can catch up.
The two documents together make a single argument: AI is accelerating its own development faster than institutions are built to handle, and the window to act is now.
What the recursive self-improvement data shows
The Anthropic Institute paper, "When AI Builds Itself," is the first time the company has released detailed internal productivity figures.1
The headline numbers: as of May 2026, more than 80% of code merged into Anthropic's codebase was authored by Claude, up from low single digits before Claude Code launched in February 2025.1 That shift compressed productivity dramatically — lines of code per engineer per day grew at two distinct inflection points: when Claude began executing code rather than only suggesting it (2025), and again when models extended their autonomous task horizon into the hours-to-days range (2026).
On the most open-ended engineering tasks — ones with no predetermined answer — Claude's session success rate reached 76% in May 2026, up from roughly 26% six months earlier.1 For research work, the picture tracks the same curve. In the company's standard "speed up this training code" benchmark, Claude Mythos Preview delivered roughly a 52× speedup over a starting baseline in April 2026; a skilled human researcher would need four to eight hours to hit 4×.1
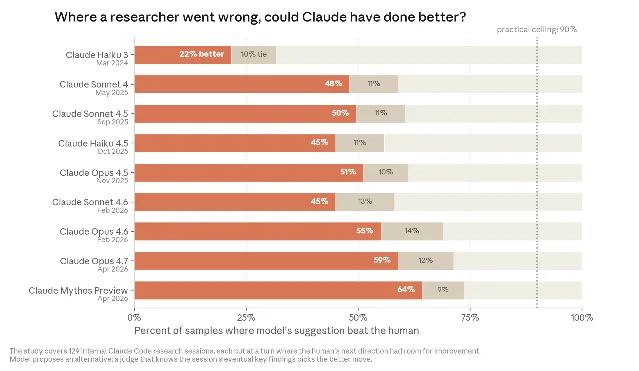
The paper's research judgment data is arguably more significant than the engineering figures. When Anthropic researchers were navigating open-ended investigations and hit a "detour" decision point — a fork where the human chose an inferior next step — Claude Mythos Preview proposed the better direction 64% of the time in April 2026, up from 51% with Opus 4.5 in November 2025.1 The human researchers in this test are among the best in the world at building AI systems. That Mythos Preview was picking better research decisions in most instances is the kind of data point that doesn't appear in public benchmarks.
The task-horizon benchmark from METR puts a frame around all of it: Claude Mythos Preview can work "at least" 16 continuous hours and is "at the upper end" of what METR can measure with existing tasks.1 The length of tasks AI can reliably complete on its own has been doubling roughly every four months.
The paper does not argue that full recursive self-improvement is imminent or inevitable. What it argues is that the trend lines point there, the company can see each component of the research-development loop being automated in sequence, and the window for deliberate coordination is closing. Anthropic says it will organize conversations with policymakers, researchers, civil society, and other AI companies in the coming months on how to build verification systems for a credible slowdown or pause — and that if such systems existed and other frontier developers slowed verifiably, Anthropic would slow too. A unilateral pause, the paper notes, only changes who the front-runner is.
The policy response: two frameworks, $350 million
Six hours after the institute paper went up, Dario Amodei published a companion essay on his personal site — simultaneously, Anthropic posted its full "Policy on the AI Exponential" framework containing two documents.23
Advanced AI Framework. The document proposes that the US government receive legal authority to block or deter deployment of any model that poses significant risk of catastrophic harm.2 The thresholds it targets: models trained on more than 10²⁵ FLOPs, at companies with more than $500M in AI revenue or more than $1B in AI R&D spend. The four risk categories the framework addresses are biological weapons uplift, large-scale cyberattacks on critical infrastructure, loss of human control over AI systems, and automated AI R&D accelerating all three.
The enforcement mechanism would attach civil penalties tied to global annual revenue, escalating with repeated violations. Transparency would be mandatory — safety evaluations published, independent evaluators given access, security programs described at a high level. Amodei explicitly argues that existing transparency laws (California, New York) are no longer enough and that "more serious and binding regulation" is needed.3
The framework also takes a position on federal preemption: Congress should not preempt state AI laws unless it enacts a federal law "at least as strong" as what Anthropic is proposing. States should retain authority over issues outside the specific safety functions of any federal framework.
Economic Policy Framework. The second document addresses labor market disruption across three unemployment scenarios: 5%, 10%, and "unprecedented."4 At 5%, the framework proposes expanding capital accounts (currently restricted to index funds) to allow workers to hold AI-company equity, alongside workforce training grants, wage insurance, and occupational licensing reform. At 10%, expanded unemployment insurance with sector-specific transition support. At the "unprecedented" level — which the framework acknowledges is novel territory — basic income, sovereign wealth models, and equity-sharing mechanisms.
Amodei's accompanying essay described AI as potentially producing "much larger disruptions to the labor market than previous technologies, and, potentially, more enduring disruptions" — and said the financing for basic income in that scenario could come from taxes on "relevant companies" or a higher capital gains rate.5
To back the proposals financially, Anthropic announced two commitments totaling $350 million:
- $200 million to an Economic Futures Research Fund to finance research trials and evaluation on the policies it considers promising4
- $150 million for a national fellowship program to help early-career professionals extend AI benefits into underserved communities4
Read Axios's full coverage: Anthropic CEO says government should block dangerous AI
Why this lands differently from prior AI safety rhetoric
Anthropic has been vocal about AI safety since its founding, so the question is what makes June 10 different from the company's standard regulatory commentary.
Three things distinguish it. First, the institute paper uses internal data: production code percentages, session success rates on real engineering tasks, actual benchmark trajectories — not hypothetical models or external evaluations. It's Anthropic saying "here is what is happening inside this building." That is a different epistemic status than a policy white paper.
Second, the scale of the financial commitment is unusual for an AI company voluntarily backing proposals that explicitly target its own industry. The $350M figure matches or exceeds most government AI safety funding programs.
Third, the timing. The recursive self-improvement data lands eight days after Anthropic's confidential S-1 filing, as the company is actively preparing to go public. Investors will now have to factor the possibility of blocking regulation — proposed by the company seeking their capital — into their models.
What to watch
The practical test for the Advanced AI Framework is whether the regulatory proposals gain any traction in Washington, where, as Axios noted, they "go far beyond anything currently under serious consideration."3 Trump's June 2 executive order focused on promoting AI innovation rather than imposing safety blocks; Amodei wrote directly that it "should go further."
The practical test for the recursive self-improvement work is whether other frontier labs — OpenAI, Google DeepMind, xAI — participate in the verification and coordination conversations Anthropic says it will convene. A coordinated slowdown or pause requires agreement from labs in multiple countries; the paper is clear that a unilateral step by one company accomplishes little beyond changing who leads.
For Anthropic's IPO narrative, the filing tension is real. The company is simultaneously the fastest mover on Mythos-class capability (Fable 5 launched June 9) and the loudest voice in the industry for blocking the fastest movers.
围绕这条内容继续补充观点或上下文。